Independent study in few-short learning architecture
Aug 2021 - Dec 2021 — Raleigh, North Carolina
Repositories
— zsl_sae_matlabOverview:
Zero-shot learning (or ZSL) is a field of study in deep learning to use a preexisting model, without altering it, to perform a task (such as classification) it has never performed before. An example with classification would be to classify a set of classes it has not been trained on. Using a semantic auto-encoder, the final feature layers of some classifier can be projected into some meaningful latent space of varying dimensionality. This semantic space is then used as the basis of classification, rather than using the feature-space or label / classification space. Depending on how classification is performed, this semantic auto-encoder solution for the ZSL paradigm is suprisingly effective. An implementation and analysis of this (work of Kodirova, Xiang, and Gong in 2017) is made, as seen in the report at the bottom of this page. More detail about ZSL and this study is all fully recorded in the report.
In addition, a decoder is used (independent of the SAE for ZSL) for purely cosmetic purposes to visualize the spaces being worked in, and gain a more intuitive understanding of how this SAE works how it does. The figure below shows both the classifier, the intermediate SAE for ZSL, as well as the futile decoder.
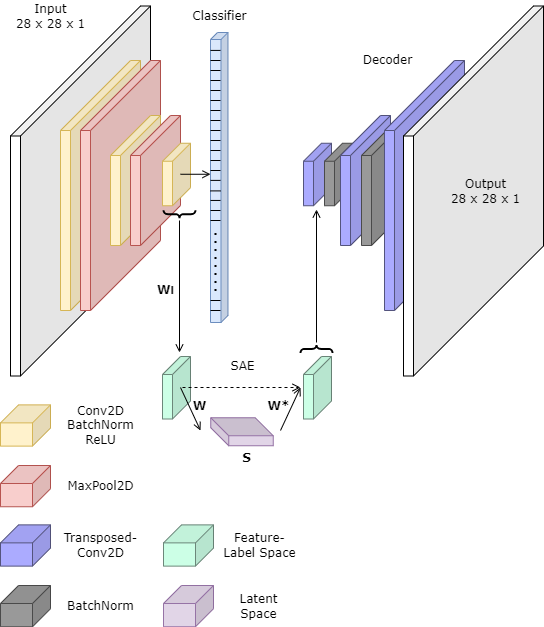
Fig 1: Model architecture used in this study
Personal Statement:
I decided to take ECE 633 (Individual Topics in Electrical Engineering, or commonly refered to as an independent study) at NC State University so I could have a masters project, similar to a thesis, while completing my class-based masters. Though this project is significantly smaller than a thesis, it still gave me a 'taste' of what a thesis-based masters would be like.
The original idea I had has been in my mind for quite sometime, and in-fact, I still have yet to implement it. The idea has to do with initial impressions, and how, as humans, we greatly take in / consider / account for information when it is a first impression. Therefore, I proposed a simple neural network architecture which dynamically can append nodes to the final classification layer, based off whether a point of training data has never been seen before during training. This would not be trained in the traditional sense, but rather sequentially trained. Therefore, initial training is very extensive and slow, but exponentially decreases the more classes are added; the model learns at the rate which it knows. E.g., if hand-drawn numeric characters are attempted to being learned by the model for classification, then first only 0's are trained, then mixes of 0's and 1's, then mixes of 0, 1, 2's, etc. until all classes are learned (where each initial impression appends a new classification node, previous weights + biases, and dynamically reconfigures itself accordingly per new class). There are many ways to accomplish this dynamic updating, but the simpliest way is to consider the linear combination of the previous layer to existing nodes, and realise that this linear combination refers to a new node. For the first instance, a new layer (or multiple layers) with no bias and unit weights can be implemented to priotize that linear combination to a select node while attempting to unalter the remaining classifications. Or this step (the appending of new layers) can be completely bypassed by exponentially increasing the classification rate to the new node so that after softmax, it is prefered over the rest. The problem with this, would be a greater misclassification rate on already learned nodes. This also begs the question, on a dynamic classification model where the classification nodes are not held in the same layer. Regardless, this dynamically changing network could also be implemented with unsupervised learning, which was my original intention for the independent study. Where instead of knowing what classes are within a training set, there can be a set number of classification nodes to correspond to features within an image. When a new, unseen feature is introduced to the model, it can determine a confidence level of whether it thinks it has seen this feature before. If not, append a new node. If so, then continue training. This can selectively choose what features are deemed most important, similar to how a CNN works. Then, this can be used as a 'base' model to extract further, class-based information on the dataset trained which will significantly speed up the training process. E.g., this unsupervised model can be trained on faces. The model will select features, becoming some base 'feature model' for the face dataset. Then, if someone wants a model to read emotions, this feature model can act as a base with only 1-2 additional layers added for classification where gradient descent is only done on those 1-2 layers (the feature model remains unaltered). Therefore, instead of making a whole new face model just for emotion extraction, you just use the face feature model and append to it.
I still have to attempt this, however my advisor Dr. Tianfu (Matt) Wu dissuaded me for two reasons. One, for a single semester independent study, this is a lot. And two, I am working in the feature space instead of the latent space, which has severe limitations in terms of model flexibility.
In addition, I really wish I spent more time on this project. In all, this report is less than a couple weeks worth of work severly crammed in at the end of my degree. Since I completed my masters education in 1 semester after undegrad, every semester I overloaded the amount of classes and work I had to to. The semester this project was done is no exception. If I could put my full attention into this project, significantly better results and (I believe) potentially some novelty could have been achieved.
Literature:
Voros_Arpad_ECE633_study.pdf